Talking is a natural and intuitive way for people to interact with AI assistants. However, most research evaluates Large Audio Models using a set of static benchmarks, which are effective for assessing isolated tasks but may not capture how well models can interact with people in real-world scenarios. Therefore, we introduce Talk Arena, an interactive open platform to evaluate Large Audio Models through interactions with users in real-world settings. We used Talk Arena's dynamic evaluation to benchmark five large audio models, and correlated these results to those on 18 static benchmarks in speech comprehension.
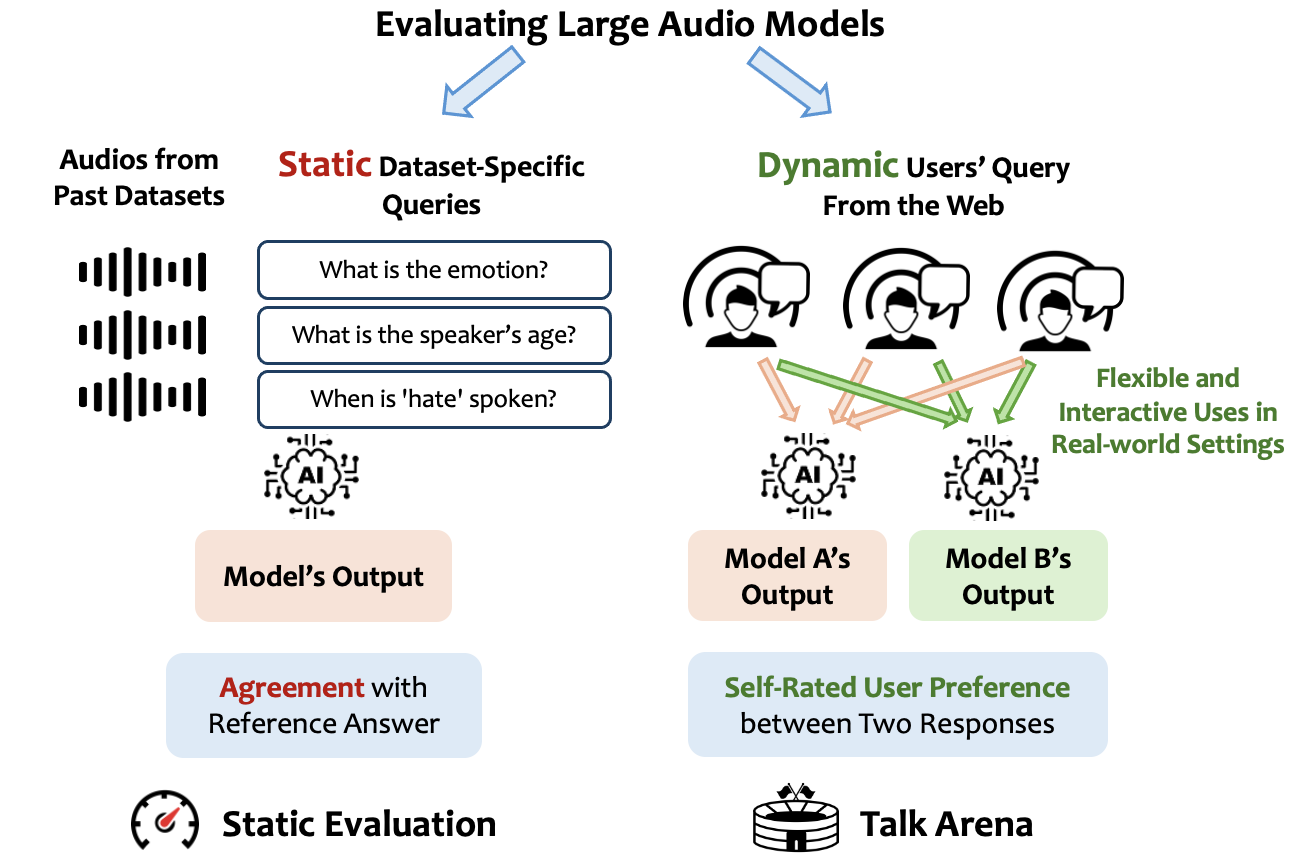
Recent efforts towards creating multimodal models have resulted in LLMs capable of processing audio inputs such as speech. Speech is a low-friction interface which expands social and phonetic interaction opportunities with end users. Prior work has benchmarked audio models on a set of disjoint static audio tests such as sarcasm or humor detection. However such static benchmarks lack the complex dynamics of real user interactions and preferences. Inspired by arena-style evaluations for text LLMs we introduce Talk Arena, an open platform for evaluating Large Audio Models with pairwise human preferences. Talk Arena helps to reveal insights on:
- Which Large Audio Model users prefer the most? Users vote their preferences with self-initiated prompts, which better reflects the actual user experience.
- Are static speech comprehension benchmarks predictive of user preferences in interactive settings? Talk Arena reveals a gap between the mainstream evaluation method for audio models and actual user preferences.